


Are you looking to classify data with AI? If you’re set on creating your first classifier to automatically distinguish between various classes, you’ve found the ideal resource! Back in the day I wrote a post about Support Vector Machines (check it out here), but in this post I’ll now be focusing on another great tool to achieve this: Logistic Regresion. Join me as we dive into hands-on coding with Python, learning the ins and outs of data classification using AI. Let’s begin our journey!
Why is it called Logistic Regression?
Logistic Regression, despite its name suggesting a regression algorithm, is a widely used method for binary classification. The nomenclature “Logistic Regression” originates from the logistic function at the heart of this algorithm, which is crucial for transforming linear regression outputs into probabilities. This section delves into the logistic function, also known as the sigmoid function, its introduction, and its pivotal role in Logistic Regression, shedding light on the reasoning behind the algorithm’s name.
Introducing: The Sigmoid Function
At the core of Logistic Regression lies the sigmoid function, a mathematical equation that maps any real-valued number into a value between 0 and 1. This characteristic makes it exceptionally suitable for binary classification tasks, where the outcome needs to be categorized into one of two possible classes. The sigmoid function is defined as:
(1) 
where z represents the input to the function, which is typically a linear combination of the input features ( , where w represents weights, x represents features, and b is the bias). The exponential function ensures that the output of the sigmoid function smoothly transitions from 0 to 1, providing a probabilistic interpretation of the input features belonging to a particular class.
, where w represents weights, x represents features, and b is the bias). The exponential function ensures that the output of the sigmoid function smoothly transitions from 0 to 1, providing a probabilistic interpretation of the input features belonging to a particular class.

Figure 1: A representation of the Sigmoid function that is used by the Logistic Regression algorythm to determine the class of a certain evaluated case. As you can see, it can map any value of  to values between 0 and 1 which will be tunned and further employed to define the probability of a case of belonging to a certain class.
to values between 0 and 1 which will be tunned and further employed to define the probability of a case of belonging to a certain class.
Why “Logistic”?
The term “logistic” in Logistic Regression is directly linked to the logistic function’s role in the algorithm. The logistic (or sigmoid) function’s S-shaped curve is ideal for binary classification because it can take any real-valued number and map it onto a value between 0 and 1. This mapping is interpreted as the probability that a given input belongs to a particular class, which is precisely what is needed in binary classification tasks.
Moreover, the logistic function introduces non-linearity into the model, which is essential because the relationship between the input variables and the probability of the outcomes is not linear. This non-linear transformation allows Logistic Regression to handle cases where the relationship between the predictor variables and the outcome is not straightforward, making it a powerful tool for classification despite its simplicity.
In summary, Logistic Regression is so named because it employs the logistic (sigmoid) function to convert linear regression outputs into probabilities. This conversion is crucial for performing binary classification, allowing the model to predict the likelihood of data belonging to one class or the other. The introduction of the sigmoid function is a key component of Logistic Regression, providing the necessary framework for understanding the algorithm’s name and its application in machine learning.
Classify data with AI: The math behind Logistic Regression
Tuning Logistic Regression involves adjusting its parameters to improve the model’s performance for a particular dataset. This process is crucial for optimizing classification accuracy and ensuring the model generalizes well to unseen data. Understanding the mathematical foundation behind tuning Logistic Regression can provide deeper insights into how adjustments to the model’s parameters influence its behavior and performance. This section explores the key concepts, including the cost function, regularization, and optimization algorithms, which are central to effectively tuning a Logistic Regression model.
The Cost Function in Logistic Regression
The cornerstone of tuning Logistic Regression is its cost function, also known as the log loss, the binary cross-entropy loss or the negative log likelihood (you can find an amazing explanation on this matter right here). The cost function measures the difference between the predicted probabilities and the actual class labels, guiding the optimization process to minimize errors. It is defined as follows::
(2) ![\begin{equation*} J(\mathbf{w}, b) = -\frac{1}{m} \sum_{i=1}^{m} \left[y^{(i)} \log(\hat{y}^{(i)}) + (1 - y^{(i)}) \log(1 - \hat{y}^{(i)})\right]\end{equation*}](https://curielrodrigo.com/wp-content/ql-cache/quicklatex.com-1f022720db5ed69e904c640f1ed31fb4_l3.png "Rendered by QuickLaTeX.com")
where
 is the number of training examples
is the number of training examples- is the true label (target value) of the th training example
- is the predicted probability of the th training example being in class 1
- and are the parameters of the logistic regression model (weights and bias).
 is the number of training examples
is the number of training examples is the true label (target value) of the
is the true label (target value) of the  th training example
th training example is the predicted probability of the
is the predicted probability of the  and
and Regularization: Balancing Complexity and Performance
Regularization is a technique used to prevent overfitting by penalizing overly complex models. In the context of Logistic Regression, regularization is applied by adding a regularization term to the cost function, which adjusts the magnitude of the model’s parameters. There are two main types of regularization:
- L1 regularization (Lasso): Adds the absolute value of the magnitude of coefficients to the cost function. This can lead to some coefficients being reduced to zero, effectively performing feature selection.
- L2 regularization (Ridge): Adds the square of the magnitude of coefficients to the cost function. This tends to distribute the penalty among the features and leads to smaller, but non-zero, coefficients.
The regularized logistic regression cost function, denoted as  , is defined as:
, is defined as:
(3) ![\begin{equation*} J_{\text{reg}}(\mathbf{w}, b) = -\frac{1}{m} \sum_{i=1}^{m} \left[y^{(i)} \log(\hat{y}^{(i)}) + (1 - y^{(i)}) \log(1 - \hat{y}^{(i)})\right] + \frac{\lambda}{2m} |\mathbf{w}|^2\end{equation*}](https://curielrodrigo.com/wp-content/ql-cache/quicklatex.com-28af96533e0e6c5889d2fcdff7a8197f_l3.png "Rendered by QuickLaTeX.com")
where
- is the number of training examples
- is the true label of the th training example
- is the predicted probability of the th training example being in class 1
- and are the parameters of the logistic regression model (weights and bias)
- is the regularization parameter. The regularization term is added to the cost function to penalize large values of the weights , which helps prevent overfitting by encouraging simpler models.
 is the regularization parameter. The regularization term
is the regularization parameter. The regularization term  is added to the cost function to penalize large values of the weights
is added to the cost function to penalize large values of the weights Given this regularized logistic regression cost function, our goal is to minimize it with respect to the parameters  and
and  , thereby honing our model’s predictive prowess. This task is where optimization algorithms come into play. Techniques such as gradient descent, stochastic gradient descent, and their variants endeavor to navigate the landscape of the cost function, iteratively adjusting the parameters to descend towards the optimal solution. As I consider gradient descent is a whole topic on its own, I’ll be writting another article about it soon! Stay tunned for that on my AI section.
, thereby honing our model’s predictive prowess. This task is where optimization algorithms come into play. Techniques such as gradient descent, stochastic gradient descent, and their variants endeavor to navigate the landscape of the cost function, iteratively adjusting the parameters to descend towards the optimal solution. As I consider gradient descent is a whole topic on its own, I’ll be writting another article about it soon! Stay tunned for that on my AI section.
When should I use Logistic Regression?
Logistic Regression is a foundational tool in the realm of machine learning, renowned for its simplicity and efficiency in particular scenarios. Recognizing when to employ Logistic Regression can significantly enhance your ability to choose the most appropriate algorithm for your specific task. It is particularly advantageous in the following situations:
- Binary classification tasks: Logistic Regression is most effective for binary classification problems, where the outcome is to predict one of two possible classes. This algorithm excels at modeling the probability that a given input belongs to a particular class, making it ideal for scenarios where you need to categorize data into two distinct groups. Its simplicity and interpretability make it a go-to choice for binary classification.
- Probabilistic outcomes: If your project requires not just classification but also an understanding of the probability behind those classifications, Logistic Regression is your ally. It provides probabilities for each class, which can be crucial for decision-making processes where you need to assess risk or uncertainty.
- Small to medium-sized datasets: Logistic Regression can perform well on smaller datasets or when dealing with a moderate number of features. It’s less prone to overfitting compared to more complex models, especially when regularized properly, making it a suitable option when the amount of data is limited.
- Interpretability is a priority: One of the significant advantages of Logistic Regression is its interpretability. The model’s coefficients can be directly related to the odds of the dependent variable, providing clear insights into how different predictors affect the outcome. This is particularly valuable in fields like medicine or social sciences, where understanding the influence of variables is as important as the prediction itself.
- Baseline model for comparison: Given its simplicity and the fact that it requires fewer computational resources, Logistic Regression is often used as a baseline model. It can provide a quick and straightforward assessment of how challenging a classification problem might be, against which more complex models can be compared.
However, it’s essential to be aware of its limitations. Logistic Regression might not perform well with non-linear problems, very large datasets, or situations where the relationship between features is complex. In such cases, exploring more sophisticated algorithms could be more beneficial. I usually like to provide some background behind the statistics and math that build the algorythms, so let’s go deeper in the basics of linear regression before we see the actual implementation.
Linear Regression: The code
To demonstrate the math behind tuning Logistic Regression without using pre-built machine learning libraries (except for downloading the breast cancer dataset), I’ll guide you through a Python script. This script will include:
- Loading a certain dataset for training and testing our classifier. For this excercise, I have chosen the Breast Cancer dataset (I’ll be using sklearn.datasets just for downloading).
- Implementing Logistic Regression from scratch, including the sigmoid function, cost function, gradient descent for optimization, and adding L2 regularization.
- Training the Logistic Regression model on the dataset.
- Evaluating the model’s performance with a simple accuracy calculation.
Please note, this example is educational and simplifies many aspects of building a robust machine learning model.
'''
Code by Rodrigo C. Curiel, 2024.
Check this and more snippets at www.curielrodrigo.com
'''
# Import the sklearn library (only for loading the dataset, I promise)
from sklearn.datasets import load_breast_cancer
import numpy as np
# Load the breast cancer dataset
data = load_breast_cancer()
X = data.data # Features
y = data.target # Target variable (labels)
# Standardize features (mean = 0, standard deviation = 1)
X = (X - np.mean(X, axis=0)) / np.std(X, axis=0)
# Add intercept term (bias term) to the features (X matrix)
# This is necessary for the logistic regression model to learn the bias term
X = np.concatenate([np.ones((X.shape[0], 1)), X], axis=1)
# Split dataset into training and test sets
np.random.seed(42) # Set random seed for reproducibility
indices = np.random.permutation(X.shape[0]) # Generate random indices
split_idx = int(0.8 * X.shape[0]) # 80% of data for training, 20% for testing
train_idx, test_idx = indices[:split_idx], indices[split_idx:]
X_train, X_test = X[train_idx], X[test_idx] # Features for training and testing
y_train, y_test = y[train_idx], y[test_idx] # Labels for training and testing
# Sigmoid function
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# Cost function with L2 regularization
def cost_function(theta, X, y, lambda_):
m = len(y) # Number of training examples
h = sigmoid(X.dot(theta)) # Hypothesis function
# Calculate logistic loss with regularization term
cost = (-1/m) * (y.T.dot(np.log(h)) + (1 - y).T.dot(np.log(1 - h))) + (lambda_ / (2*m)) * np.sum(np.square(theta[1:]))
return cost
# Gradient descent with L2 regularization
def gradient_descent(X, y, theta, alpha, iterations, lambda_):
m = len(y) # Number of training examples
cost_history = np.zeros(iterations) # Initialize array to store cost at each iteration
# Iterate through specified number of iterations
for i in range(iterations):
h = sigmoid(X.dot(theta)) # Hypothesis function
# Calculate gradient with regularization term
gradient = (1/m) * X.T.dot(h - y) + (lambda_ / m) * np.r_[0, theta[1:]]
theta -= alpha * gradient # Update parameters
cost_history[i] = cost_function(theta, X, y, lambda_) # Store cost for current iteration
return theta, cost_history # Return optimized parameters and cost history
# Initialize variables
theta_initial = np.zeros(X_train.shape[1]) # Initialize parameters to zeros
alpha = 0.01 # Learning rate
iterations = 1000 # Number of iterations for gradient descent
lambda_ = 1 # Regularization parameter (lambda)
# Run gradient descent to optimize parameters
theta_optimal, cost_history = gradient_descent(X_train, y_train, theta_initial, alpha, iterations, lambda_)
# Prediction function
def predict(X, theta):
return np.round(sigmoid(X.dot(theta))) # Predict using threshold 0.5
# Evaluate model accuracy on test set
predictions = predict(X_test, theta_optimal)
accuracy = np.mean(predictions == y_test) # Calculate accuracy
print(f"Model accuracy on the test set: {accuracy:.2f}")
# Confusion matrix function
def confusion_matrix(actual, predicted):
TP = np.sum((actual == 1) & (predicted == 1)) # True positives
TN = np.sum((actual == 0) & (predicted == 0)) # True negatives
FP = np.sum((actual == 0) & (predicted == 1)) # False positives
FN = np.sum((actual == 1) & (predicted == 0)) # False negatives
return np.array([[TP, FN], [FP, TN]]) # Return confusion matrix
# Display confusion matrix
confusion_matrix = confusion_matrix(y_test, predictions)
print("Confusion Matrix:")
print(confusion_matrix)Unlike my example when I did the article about classification with SVMs, this code uses plain simple Python to implement the math behind the concept of Logistic Regression to classify the dataset I chose this time. In factm the confusion matrix this snippet retrieves is much more promissing!
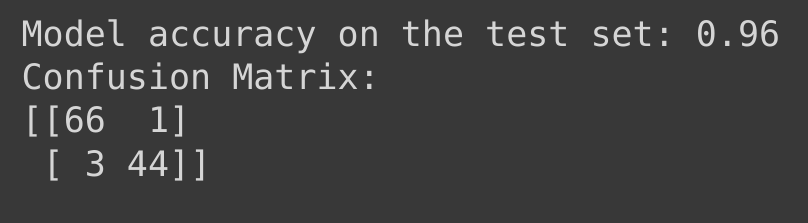
Figure 2: Confusion matrix and model accuracy achieved after running this snippet.
Conclusion
In this article, we explored the fundamental concepts of Logistic Regression and applied them to perform binary classification on the Breast Cancer dataset (without any libraries!) Did you enjoy the read? I hope this information proves helpful! Let me know what are your ideas and applications of Logistic Regression and check my other entries for learning more in future posts!
No responses yet