


Are you looking to classify data with AI? If you’re set on creating your first classifier to automatically distinguish between various classes, you’ve found the ideal resource! In this post, we’re focusing on Support Vector Machines (SVMs) to effectively meet that particular necessity. This algorithm is widely acclaimed for their efficiency in both classification and regression tasks. Join me as we dive into hands-on coding with Python, learning the ins and outs of data classification using AI. Let’s begin our journey!
Table of contents
When should I use Support Vector Machines (SVM)?
SVMs are a versatile tool in machine learning, known for their effectiveness in various scenarios. Understanding when to use SVMs can help you make informed decisions in selecting the right algorithm for your task.
SVMs are particularly well-suited for the following situations:
- Binary classification with “clear separation”: As I will explain later in this article, SVMs are particularly useful when dealing with binary classification tasks where there is a clear separation between two classes. If your data can be distinctly divided and is not overlapping, SVMs are a strong choice. The algorithm’s ability to maximize the margin between classes ensures robust separation for unseen data!
- High-dimensional data: As long as the classes are well defined, SVMs also excel in high-dimensional spaces, making them a valuable tool for scenarios involving more than two classes or datasets with an extensive list of features. However, it’s important to note that as datasets become increasingly high-dimensional, the mathematical complexity behind creating SVMs also escalates significantly. While SVMs are well-suited for applications such as text classification, image recognition, and bioinformatics, where dimensionality is often substantial, their complexity grows proportionally with higher dimensions.
- When you seek robust generalization: SVMs are designed to find the hyperplane that maximizes the margin between classes, which promotes better generalization to unseen data. If your goal is to build a model that can make accurate predictions on new, unprocessed data, SVMs are a reliable choice.
- Supporting small datasets: As you will see shortly, SVMs can be very effective when you have a relatively small dataset. They tend to perform well with limited training samples due to their emphasis on support vectors, which are the critical data points defining the hyperplane.
- Cases with outliers: SVMs are robust to outliers in the data. Outliers have less impact on the hyperplane’s position and orientation since the algorithm primarily relies on support vectors, which are usually unaffected by outliers.
It’s crucial to take into account factors like computational complexity and model interpretability. SVMs may not be the optimal choice for handling very large datasets or situations where interpretability is of crucial importance. Now that we’ve discussed some key considerations for when to use SVMs, let’s go deeper into the fundamental concepts behind their operation!
SVMs’ basic concepts
As briefly stated before, SVMs are a type of supervised machine learning algorithm primarily used for classification tasks, that is, identifying unknown cases and categorizing them into the best-fitting category. The core idea behind SVMs is to find a hyperplane in an N-dimensional space (N — the number of features) that distinctly classifies the data points. Let’s formaly define some important concepts for understanding SVMs.
- Hyperplane: In the context of SVMs, a hyperplane is a decision boundary that separates different classes of data. For a 2-dimensional dataset, this hyperplane is a line, while in 3 dimensions, it’s a plane. Even if it is not imaginable, in higher dimensions we still refer to it as a hyperplane. The simplest of them all cases is a straight line that would be able to separate 2 well defined datasets, to which equation 1 is a great fit.
(1)

Where
– represents a vector usually called the weight vector.
– represent a constant normally reffered to as the bias.
– signifies the different values a feature can obtain on the domain of the possible spectrum our use case requires. - Support Vectors: Support vectors are specific data points from a given dataset that are crucial in defining the decision boundary (hyperplane). These data points essentially mark the boundaries where the hyperplane could become critical. In the subsequent sections, I will describe the mathematical algorithm behind this in greater detail. For now, suffice it to say that it “fine-tunes” the hyperplane to maximize the margin between these support vectors and the hyperplane.
- Margin: The margin refers to the distance between the hyperplane and the nearest data point from either class. The primary objective of SVM is to maximize this margin. A larger margin implies better generalization of the algorithm to new, unseen data. For those inclined towards mathematical details, the margin is formally defined as shown in equation 2.
(2)

 signifies the different values a feature can obtain on the domain of the possible spectrum our use case requires.
signifies the different values a feature can obtain on the domain of the possible spectrum our use case requires. 
These three concepts are the main building blocks of SVMs and are crucial for understanding how SVMs work and what they aim to achieve in a classification task. You can see a graphical representation over Figure 1:

Figure 1: A representation of 2 sets of data (red and green) mapped on a cartesian plane formed by 2 features and
and  . The hyperplane denotated by a blue line illustrates the sweet spot for when the margin is optimized for having the support vectors as far as possible from the hyperplane itself.
. The hyperplane denotated by a blue line illustrates the sweet spot for when the margin is optimized for having the support vectors as far as possible from the hyperplane itself.
The optimization problem (for my fellow math geeks)
So the big question is: How do we ensure that the margin yields the most appropriate hyperplane, that is, the one that ensures the most cases (seen or unseen) will be correctly classified? As we delve into this topic, we encounter an optimization challenge. SVMs are suitable for handling multi-class scenarios, but the higher you go the calculus behind them becomes more extreme. Therfore, in this post I’ll address one of the simplest cases: binary classification, that is, the case where the dataset’s features yield only two possible outcomes (dog or cat, bush or tree, A or B, etc.). Let’s explore how SVMs optimize the margin, enhancing their ability to accurately assign labels to unseen data after training.
Optimization restrictions
The goal is to find the values of  and
and  that maximize the margin while correctly classfying the inputed data. In simpler terms, we want to make sure that
that maximize the margin while correctly classfying the inputed data. In simpler terms, we want to make sure that  , where
, where  signifies the model’s output to indicate a certain input corresponds to either of two classes used on the training process.
signifies the model’s output to indicate a certain input corresponds to either of two classes used on the training process.
Lagrangian formulation
To handle the constrained optimization problem, SVM uses the Lagrangian formulation (check more about that here). The Lagrangian formulation is a technique used in optimization to convert a constrained optimization problem into an unconstrained one by introducing Lagrange multipliers for each constraint. In SVMs, the primary goal is to maximize the margin while correctly classifying data points, and this formulation helps achieve that. It introduces Lagrange multipliers ( ) for each constraint as shown in equation 3
) for each constraint as shown in equation 3
(3) ![\begin{equation*} \text{L (}\mathcal{L}\text{)} = \frac{1}{2}|w|^2 - \sum_{i=1}^{N} \alpha_i [y_i(w \cdot x_i + b) - 1] \end{equation*}](https://curielrodrigo.com/wp-content/ql-cache/quicklatex.com-aa95d408d2f85f35ff9b64608d0d2f51_l3.png "Rendered by QuickLaTeX.com")
Where:
–  is the number of training samples.
is the number of training samples.
– is the Lagrange multiplier associated with each constraint.
Deriving the Dual Problem and finding the optimal hyperplane
SVMs derive the dual problem by taking the derivative of the Lagrangian with respect to and and setting them to zero. Solving this dual problem leads to the determination of and . The derivative of the Lagrangian with respect to is given equation 4
(4) 
And the derivative of the Lagrangian with respect to is described in equation 5.
(5) 
Solving the dual problem yields the values of , and from these, we can calculate and to determine the optimal hyperplane. I have defined the final magic values under equations 6 and 7, both for any support vector  where
where  .
.
(6) 
(7) 
The solution to the dual problem, which provides us with the values of and , defines the hyperplane in SVM. This hyperplane is unique because it maximizes the margin between data points of different classes while ensuring correct classification. Notably, not all data points are equally influential in determining this special hyperplane. Only a specific set of data points, known as “support vectors,” holds significance.
These support vectors are associated with non-zero Lagrange multipliers . In essence, these values identify which data points play a crucial role in shaping the hyperplane. They effectively “support” the hyperplane by specifying its position and orientation. When we solve the dual problem and obtain the values of and , we are effectively uncovering the mathematical representation of the hyperplane that optimally separates the classes. This hyperplane’s position and orientation are precisely determined by the values and the support vectors.
While the mathematics behind this basic example is relatively straightforward, dealing with higher numbers of features and an increased number of classes can quickly become complex and challenging to solve manually. Fortunately, our friends from Scikit-learn come to save the day with their reliable and plug-and-play solution where we can easily input our datasets and obtain various measurements and valuable insights about the models themselves. Let’s explore how to implement this library in a real-world scenario
Implementing SVMs in Python
In this article, we’ll be working with the well-known Iris dataset. This dataset is a classic benchmark in machine learning and is often used for classification tasks because it contains samples of three different species of iris plants, with 50 samples per class. Each sample is described by four features: sepal length, sepal width, petal length, and petal width. For the purpose of this demonstration, we’ll focus on binary classification, specifically distinguishing between two classes within the Iris dataset. Moreover, I have prepared the code so it will only use 2 of these 3 classes (Setosa and Versicolor) so it matches with the mathematical explanation about the binary classification tasks.
'''
Code by Rodrigo C. Curiel, 2024.
Check this and more snippets at www.curielrodrigo.com
'''
# Import the required libraries for this example
# Make sure to have them installed in your Python environment
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn import datasets
import seaborn as sns
# From here, all these imports are used for evaluating the output model
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
# Load the Iris dataset and separate the features (X) form the labels (y)
iris = datasets.load_iris()
X = iris.data
y = iris.target
# We are interested in classifying Setosa (class 0) and Versicolor (class 1)
# Filter the data for Setosa and Versicolor classes only
X = X[y != 2]
y = y[y != 2]
# Split the data into training, validation, and testing sets
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2)
X_valid, X_test, y_valid, y_test = train_test_split(X_temp, y_temp, test_size=0.8)
# Create an SVM classifier with a linear kernel.
# This is where we input equation 1 into the model
# This tells Sklearn we need a binary classification based on a linear hyperplane
classifier = SVC(kernel='linear')
# Train the classifier on the training data
classifier.fit(X_train, y_train)
# Make predictions on the validation data
y_valid_pred = classifier.predict(X_valid)
# Calculate accuracy on the validation set
accuracy_valid = accuracy_score(y_valid, y_valid_pred)
print(f"Validation Accuracy: {accuracy_valid*100:.2f}%")
# Make predictions on the test data
y_test_pred = classifier.predict(X_test)
# Calculate accuracy on the test set
accuracy_test = accuracy_score(y_test, y_test_pred)
print(f"Test Accuracy: {accuracy_test*100:.2f}%")
# Calculate and print confusion matrix
conf_matrix = confusion_matrix(y_test, y_test_pred)
print("Confusion Matrix:")
print(conf_matrix)
# Plot confusion matrix as a heatmap
plt.figure(figsize=(6, 4))
sns.heatmap(conf_matrix, annot=True, fmt="d", cmap="Blues")
plt.xlabel("Predicted")
plt.ylabel("Actual")
plt.title("Confusion Matrix")
plt.show()Results interpretation
In our implementation of SVMs for binary classification on the Iris dataset, we successfully trained the model and made predictions. After training the SVM, we applied it to classify diverse data points from the Iris dataset. The SVM identified a hyperplane that maximizes the margin between the two selected classes while correctly classifying the data. The predictions made by the SVM are the results we obtained, which I have printed and pasted below in Figure 2. Note your results can be a little bit different, as well as my further comments come from my own results I got when running the code.
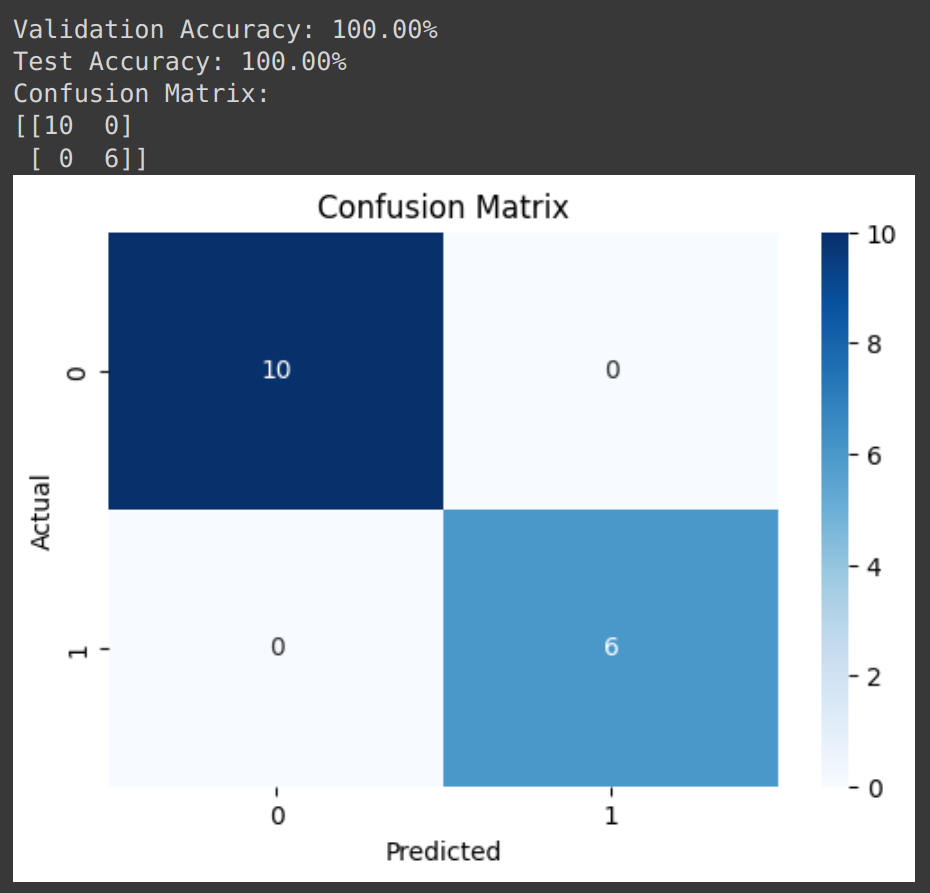
Figure 2: These are the results I obtained after running the code. They should be a little different from yours!
Normally speaking, you don’t really want to see a classification accuracy of 100% whenever you are training a real SVM-based model as it could be indicative of an overfitted architecture. However, particularly for the IRIS dataset there are several reasons why this could happen:
- Simple Dataset: The Iris dataset is a relatively simple and well-behaved dataset with clear boundaries between classes. Specifically, the Setosa and Versicolor species (which we have chosen for classification) are usually easier to distinguish than Versicolor and Virginica.
- Effective Features: The features in the Iris dataset are quite effective for distinguishing between the species. SVMs, particularly with linear kernels, are very good at exploiting such clear feature separations.
- Small Dataset Size: The Iris dataset is small, and the sample you’ve used (by excluding the third class) is even smaller. High accuracy is easier to achieve on smaller datasets due to less variability and complexity.
- Data Splitting Method: Our method of splitting the data into training, validation, and test sets might have resulted in particularly easy-to-classify samples ending up in the validation and test sets. This can sometimes happen by chance, especially with small datasets.
- Lack of Overfitting: Since we are using a linear SVM which is a relatively simple model, there’s less risk of overfitting, which can lead to high accuracy on both validation and test sets if the dataset is inherently simple.
The predictions generated by our SVM model can be used to classify new data points, that is, data that was not included in the training process. Of course, if you have additional datasets or specific use cases in mind, you can apply this trained SVM to make accurate classifications and leave a message with your experimental outcomes down below!
Conclusion
In this article, we explored the fundamental concepts of SVMs and applied them to perform binary classification on the Iris dataset. We covered key steps, from data preparation to training the model and making predictions.
SVMs have proven to be a powerful tool for classification tasks, especially when dealing with scenarios where a clear separation between classes is essential. SVMs are robust in handling high-dimensional data and are effective even with small datasets, making them a valuable addition to your machine learning toolkit.
In conclusion, SVMs are a versatile and valuable resource for binary classification tasks. By understanding their core principles and applications, you can harness the power of SVMs to solve real-world classification challenges effectively.
Did you enjoy the read? I hope this information proves helpful! Let me know what are your ideas and applications of SVMs and check my other entries for learning more in future posts!
One response
[…] my last post we discussed how to implement object classification with SVMs. However, I’ve been also working latyely on a lot on hardware-based projects that require […]